こんにちは、ROUTE06 でソフトウェアエンジニアをしている@MH4GFです。
この記事では、urqlの Document Caching における additionalTypenames についての説明と、実運用でどのように扱うべきかという私見を書きます。最後に、提案する方針を後押しするために作成した Exchange(urql のプラグイン)を紹介します。
urql と Document Caching
urql は、主に Web フロントエンドアプリケーションで使用される柔軟性と拡張性に優れた GraphQL クライアントです。
GraphQL クライアントライブラリにはパフォーマンスを向上させるためのキャッシュ機構が用意されていることが多いですが、urql はデフォルトではDocument Cachingと呼ばれる概念を使用します。
Document Caching は query と variables をハッシュ化したものをキャッシュキーとして、クエリレスポンスをキャッシュします。そしてミューテーションの実行タイミングで関連する __typename を含むキャッシュを破棄し、クエリを再実行します。
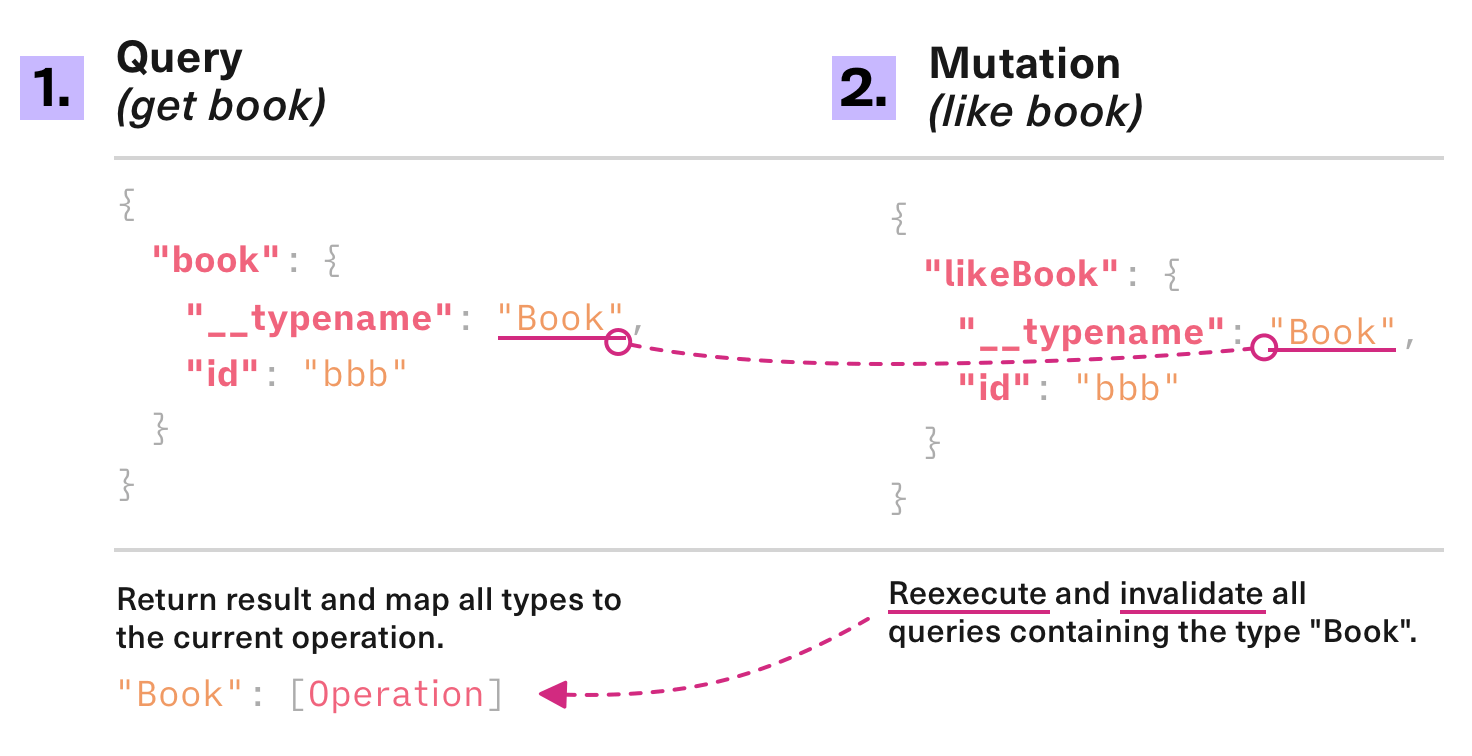
(画像は https://formidable.com/open-source/urql/docs/basics/document-caching/ より引用)
もう一つの定番な GraphQL クライアントである Apollo Client で採用されている正規化されたキャッシュ(Normalized Cache)では、ミューテーション実行時の状況でキャッシュを自動更新してくれるパターンとキャッシュの手動書き換えが必要になるパターンがありますが、urql の場合一律でクエリの再実行となるため管理がとても楽です。
Apollo と比べてネットワークリクエストは富豪的になりキャッシュ効率は落ちますが、実装者がキャッシュを手動で操作することがないためバグを生みにくいのも大きなメリットです。パフォーマンスに制約が少ない to B アプリケーションでは有用なケースが多いかと思います。
キャッシュアルゴリズムの詳細は公式ドキュメントのDocument Cachingのページに簡潔にまとまっているため、そちらも読んでみてください。
Document Caching の落とし穴
キャッシュ管理の手間が大きく減る urql の Document Caching ですが、一つだけ罠が存在します。それはレスポンスデータに含まれる __typename をもとに再実行すべきクエリを判断するため、それが見つけられないケースでは自動の再実行ができない点です。
具体的な例としては、以下のように API が空の配列を返した場合があります。
const query = `query { todos { id name } }`; const [result] = useQuery({ query }); console.log(result.data); // -> { todos: [] }
この場合、レスポンスデータに __typename が含まれていないため、Todo 型を更新するミューテーションを実行してもキャッシュが破棄されず、再実行されません。
この問題の解決策は、 additionalTypenames をコンテキストとして渡すことです。
const context = { additionalTypenames: ["Todo"] }; const query = `query { todos { id name } }`; const [result] = useQuery({ query, context });
これにより、urql がキャッシュ破棄対象として識別することができます!
この落とし穴に引っかかるよくある状況としては、配列型のデータを表示しているコンポーネントで、「データの更新や削除についてはキャッシュが更新されてデータ表示にも反映されるけど、0 件の状態からデータを作成した時は反映されないな?」というケースです。
Apollo Client から urql に乗り換えてきた方であれば問題に気づきやすいかと思いますが、「今まで REST を使っていて初めての GraphQL で urql を使う」という方は気づきにくい問題かと思います。
additionalTypenames とどう向き合うか
Document Caching の落とし穴として配列型のデータ作成時には気をつける必要があることはわかりましたが、実際の運用として「気をつける」ではミスを防ぐことは難しいため、何かしらの指針があると望ましいです。
今回提案する判断軸としては、オペレーションに含まれる配列型は全て additionalTypenames に追加するといった方針です。例えば以下のようなイメージです。
const query = graphql(` query getUsers { users { # <- Userを返す配列型 name posts { # <- Postを返す配列型 title } } }` ) const context = { // UserとPostをキャッシュ破棄の対象として加筆 additionalTypenames: ['User', 'Post'] } export const Component = () => { const [result] = useQuery({ query, context }); ... 省略 ... }
User と Post はどういった値が返ってくるかこのコード上では判断できないものの、とにかく additionalTypenames に追加します。
これはキャッシュ効率よりリスク回避に倒した判断軸です。配列型のデータを返すフィールドがデータを必ず 1 件以上返すのであれば additionalTypenames に追加する必要はないですが、それは実行時にしか判断ができません。コードや型の情報だけから読み取るのは難易度が高いため、一律で配列型を全て追加することで考えることを減らせます。
ネットワークリクエストがより増えてしまいますが、そもそも Document Caching を選択するモチベーションがキャッシュ操作のリスク回避であれば影響は少ないはずです。
このアプローチは、urqlの開発チームにも確認し問題ないと回答いただいています。
とはいえ自動テストでの担保が難しい
今回はオペレーションに含まれる配列型は全て additionalTypenames に追加するという方針を紹介しましたが、ここでさらに問題になってくるのが additionalTypenames のテスト容易性が低いことです。
今回自動テストで担保したいシナリオを「一覧に表示されているデータが空の状態で、データを作成した後、一覧にデータが追加されている」とします。
React で GraphQL リクエスト・レスポンスをテストする際にはMock Service Worker(MSW)を使いモックするのが便利ですが、上記のシナリオを MSW で表現しようとすると「1 度目のクエリリクエストのレスポンスは空に、2 度目のレスポンスはミューテーションで送った値を追加する」のようなロジックが必要になります。これではモックそのものが複雑になり、モックに対するテストになってしまうため価値のあるテストを作りづらいです。
そのため価値のあるテストを用意するとしたらバックエンドも通して検証できる E2E テストを用意するのが望ましいですが、E2E テストもあまり数を増やすと実行時間の増加や flaky なテストの発生が問題になってきます。
そのため、理想としては「プロダクトの重要なシナリオを通す数ケースの E2E テスト」 + 「additionalTypenames の追加漏れを防ぐ仕組み」で守れると望ましいです。
その後者を実現するために、urql の Exchange を作成しました。
urql-exhaustive-additional-typenames-exchange
Exchange は、urql におけるプラグイン機構です。Client に渡すことで、リクエスト・レスポンスの途中に自作のロジックを挿入することができます。
今回は urql-exhaustive-additional-typenames-exchange という Exchange を作りました。
exhaustive は「徹底的な」という意味で、これはeslint-plugin-react-hooksの exhaustive-deps ルールから着想を得ています。
この Exchange はリクエストの実行時にオペレーションに含まれる配列型を全て列挙して additionalTypenames に追加します。
利用方法のサンプルを紹介するために、前述のコードを再掲します。
const query = graphql(` query getUsers { users { # <- Userを返す配列型 name posts { # <- Postを返す配列型 title } } }` ) export const Component = () => { const [result] = useQuery({ query }); ... 省略 ... }
この GraphQL オペレーションを実行すると、additionalTypenames に自動的に "User" と "Post" が追加されます。 urql-exhaustive-additional-typenames-exchange は debug: true を渡すとコンソールに最終的な additionalTypenames を表示します。
[DEBUG] exhaustiveAdditionalTypenamesExchange: operation: {...}, additionalTypenames: ["User", "Post"]
ちょっと複雑な例として、Inline Fragment や Fragment Spread を活用している例だと以下のようになります。
// Component.tsx const query = graphql(` fragment UserFragment on User { posts { body } } query getNode { node(id: "1") { ... on User { ...UserFragment } } } `);
// コンソール出力
[DEBUG] exhaustiveAdditionalTypenamesExchange: operation: {...}, additionalTypenames: ["Post"]
node の識別・Fragment の利用などのパターンも辿って配列型を走査していることがわかります。
オペレーションに含まれる配列型を走査し自動で挿入するため、additionalTypenames にどの型を追加すべきかという判断をせずとも済むようになります。コードの修正により取得するフィールドが変わったとしても、自動で追従することが可能になります。
詳しい使い方はREADMEをご覧ください。
まとめ
今回は urql の Document Caching の説明と、どう向き合っていくと良いかについて紹介しました。まとめは以下となります。
- urql の Document Caching は大半のパターンでキャッシュの自動更新をしてくれるが、罠として配列型のフィールドのレスポンスが空の場合は再取得が動作しない その問題に対処するために additionalTypenames がある
- additionalTypenames の運用方針として、オペレーションに含まれる配列型は全て additionalTypenames に追加するのが良い これはキャッシュ効率よりリスク回避を重視している
- additionalTypenames によるリグレッションを防ぐためには「プロダクトの重要なシナリオを通す数ケースの E2E テスト」 + 「additionalTypenames の追加漏れを防ぐ仕組み」が望ましく、後者は
urql-exhaustive-additional-typenames-exchangeを使って自動で追加させると良い
ここまでお読みいただきありがとうございました。urql-exhaustive-additional-typenames-exchange への Star もお待ちしております!