データベーススキーマを動的に操り、ユーザが持ち込んだ BYODB(Bring Your Own Database)のデータベースとも連携する——こうした特殊な要件に直面したローコードプラットフォームの開発現場で辿り着いた解決策はイベントソーシングと補償トランザクションでした。
本記事では、Ruby on Rails アプリケーションでタイトルのアーキテクチャパターンを実践し、複雑な分散トランザクション問題を乗り越えた手法と、その裏にある思考プロセスをご紹介します。
前半では課題の背景として、ローコードプラットフォームと BYODB 要件がもたらす複雑性を説明します。その後、イベントソーシングや補償トランザクションをどのように適用し、整合性や回復性を確保していくのか、その具体的な実装サンプルと効果をお伝えします。
実装サンプルのリポジトリ: github.com
- 注意点
- ローコードプラットフォームの全体像
- データベース機能要件
- 技術的課題: データベース間の一貫性
- アーキテクチャ設計のアプローチ
- イベントソーシングと補償トランザクションの採用
- 最終的なアーキテクチャ
- 実装サンプル
- まとめ
注意点
ROUTE06 では、ローコードプラットフォームの開発に取り組んでいます。本記事は、開発過程で検証したアーキテクチャの実装アプローチを紹介するものです。実際のプロダクトとは異なる概念実証(PoC)であることにご留意ください。
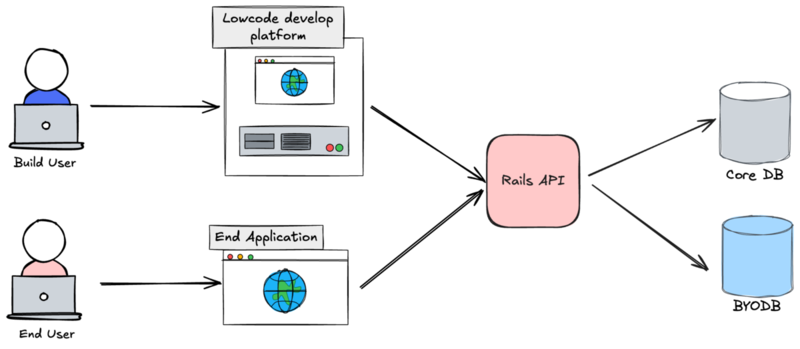
ローコードプラットフォームの全体像
開発するローコードプラットフォームは、クラウドサービス型かつ開発指向型に分類されるものです。kintone のような Web ブラウザベースのアプリケーション構築、Mendix や OutSystems のような視覚的かつ自由度の高い開発環境を目指します。
最も特徴的な機能はユーザが持ち込んだ BYODB のデータベースをローコードプラットフォームから直接操作できる点です。BYODB に接続し、テーブルの作成やカラムの変更などの DDL を全て視覚的に行うことができます。
構成要素
- ローコードプラットフォーム: ローコード開発を可能にするプラットフォーム
- エンドアプリケーション: プラットフォームで作成されたアプリケーション
- ビルドユーザ: プラットフォームを利用する開発者
- エンドユーザ: エンドアプリケーションを利用するエンドユーザ
- Core DB: ローコードプラットフォームのデータベース
- BYODB: ビルドユーザが持ち込んだデータベース
データベース機能要件
今回の BYODB 導入を前提とした場合のデータベース機能要件を整理すると以下のようになります。どれか1つの要件を満たすだけでも難易度が高いですが、それらを全て満たす必要があります。
1. BYODB の実現
- 既存のデータベースをローコードプラットフォームに簡単に接続
- 既存システムをローコードでアプリケーション化し、保有データの効果的な活用を実現
2. データベースの視覚的操作
- 専門的な SQL 知識なしで直感的な操作を可能に
- グラフィカルインターフェースによるデータベーススキーマの柔軟な変更
3. あらゆるデータベースに対応
技術的課題: データベース間の一貫性
特殊なデータベース機能要件を満たす上で、一貫性の課題に立ち向かう必要がありました。
Core DB には BYODB を管理するためのデータが登録されます。双方のデータベースは互いに依存するデータを持つため、一貫性を保つことが求められます。したがって、一方のトランザクションが失敗した場合には、不整合を回避するために、過去の状態にロールバックする必要がありました。
2Phase Commit の制約
分散トランザクションにおいて一貫性を担保する手法として、2Phase Commit があります。しかし、この手法は XA インターフェースを持つ RDBMS が前提となるため、NoSQL や Airtable などの RDB 以外のデータベースへの対応を視野に入れていた私たちにとっては、現実的な選択肢ではありませんでした。
アーキテクチャ設計のアプローチ
トランザクション戦略の比較
単一アプリケーションが持つ異なる2つのデータベース(Core DB と BYODB)間でのトランザクション戦略として2つのアプローチを検討しました。
1. トランザクションのネスト
Core DB のトランザクションの内部で、BYODB のトランザクションを開始する方法です。
- メリット:
- 原子性を確保しやすい
- 実装が比較的シンプル
- デメリット:
- BYODB コミット後にエラーが発生すると不整合が起きる
- 長時間ロック取得やレイテンシの増大
sequenceDiagram
participant API
participant DB1 as Core DB
participant DB2 as BYODB
API->>+DB1: BEGIN TRANSACTION
API->>+DB2: BEGIN TRANSACTION
API->>+DB1: INSERT
API->>+DB2: CREATE TABLE
API->>+DB2: COMMIT
API->>+DB1: COMMIT
2. トランザクションの分割
Core DB のコミット後に、BYODB のトランザクションを開始する方法です。
- メリット:
- 順次実行であるためエラー時に再試行しやすい
- マイクロサービスにおけるプラクティスを適用しやすい
- ロック取得時間が最小限に抑えられる
- デメリット:
- Core DB コミット後にエラーが発生すると不整合が起きる
- 結果整合であり同期的な一貫性は保証されない
- 処理全体で見たときのオーバーヘッドの増加
sequenceDiagram
participant API
participant DB1 as Core DB
participant DB2 as BYODB
API->>+DB1: BEGIN TRANSACTION
API->>+DB1: INSERT
API->>+DB1: COMMIT
API->>+DB2: BEGIN TRANSACTION
API->>+DB2: CREATE TABLE
API->>+DB2: COMMIT
採用方針
トランザクション分割を基本方針として選択しました。これにより、以下の利点が得られます:
- DDL を非同期処理とすることで、高速なレスポンスが可能になる
- 非同期処理による疎結合化により、モダンなアーキテクチャを適用しやすい
- DDL のロールバックに対応していないデータベースと処理を統一できる2
イベントソーシングと補償トランザクションの採用
トランザクション分割を基本方針としたものの、依然として解決が必要な問題が残っていました。それは、DDL に失敗した場合に、Core DB の状態をロールバックする処理や、逆に Core DB に合わせて BYODB を更新する再試行処理の実装です。
この問題を解決するには、過去の状態を記録し、状況に応じて柔軟に状態を変更できる仕組みが必要でした。そこで、イベントソーシングによる履歴管理と Saga パターンで用いられる補償トランザクションを採用することで、この課題に対応しました。
採用理由:
イベントソーシング: 状態追跡性の向上
- イベントログを SSOT (Single Source of Truth) とした状態射影
- システムの任意の時点の状態再構築
- イミュータブルな履歴による追跡信頼性
補償トランザクション: 回復性の強化
- 補償トランザクションによるデータ整合性の維持
- コレオグラフィの概念適用によるイベント間の相互連携
イベントソーシング:
多くのシステムでは、現在の状態を直接データベースに保存する ステートソーシング という方式が採用されています。この方式では状態更新時に古い情報が上書きまたは破棄されるため、過去の状態の再現は困難です。
一方、今回採用した イベントソーシング はシステムの状態変更をイベントとして逐次記録し、これらのイベントから現在の状態を再構築するアーキテクチャパターンです。 すべての変更履歴が保持されるため、システムの状態がどのように変化してきたかを追跡できるという特徴があります。
Saga パターン:
Saga パターンは、分散システムにおけるトランザクション管理を目的とした設計手法であり、一連のローカルトランザクションを順次実行することで、最終的な一貫性を実現します。一般的にはマイクロサービスアーキテクチャで採用されることが多いですが、補償トランザクションやコレオグラフィなどの概念は、他の分散システムにおいても部分的に活用可能です。
最終的なアーキテクチャ
採用したアプローチを具体的なアーキテクチャに落とし込んだものが下図になります3。
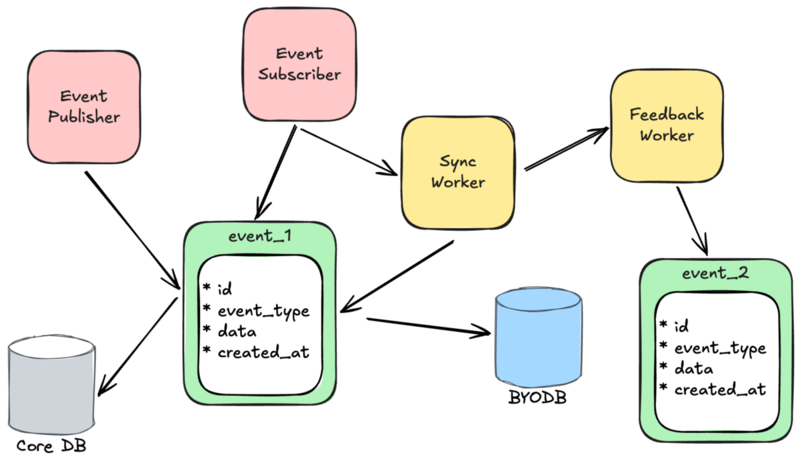

イベントソーシングを実現するコンポーネント
Event Publisher
- ユーザーリクエストをトリガーとしてイベントを発行
Event Subscriber
- イベントの発行をトリガーに非同期処理を起動
非同期処理を実現するコンポーネント
SyncWorker
- イベントに基づいた非同期処理を実行
FeedbackWorker
- SyncWorker の処理結果に応じてイベントを発行
- 処理の成否に基づき、補償トランザクションを実行
実装サンプル
上述のアーキテクチャには複数のコンポーネントがありますが、これらは全て Rails と複数の Gem 群で実現できます。サンプルのソースコードを通じて紹介します4。
リポジトリ: github.com
中核となる Gem
-
- 説明:
- イベントソーシングのための Ruby/Rails ライブラリ
- イベントの保存、ストリーミング、再生を可能にする
- サンプルでの役割:
- データベーススキーマ変更のイベント発行
- 非同期処理をトリガーするためのイベント購読
- システムの任意の時点の状態再構築
- 説明:
-
- 説明:
- Rails 7.1 で導入された軽量な非同期ジョブキューイングシステム
- データベースベースのジョブキューで、柔軟な非同期処理を実現
- サンプルでの役割:
- データベース作成や変更などの DDL を非同期実行
- 分散トランザクションにおけるジョブの管理
- 説明:
-
- 説明:
- Ruby の高性能で柔軟なデータベースツールキット
- 複数のデータベースに対する抽象化レイヤーを提供
- サンプルでの役割:
- 外部データベース(BYODB)への接続
- データベーススキーマの動的変更
- 説明:
処理の流れ
ビルドユーザがテーブル作成をリクエストするシナリオを用いて説明します。
以下の Curl コマンドは、新しいテーブルを作成するリクエストを示しています。
curl -X POST http://localhost:3000/table/create \ -H "Content-Type: application/json" \ -d '{"name": "my_new_table_123"}'
ユースケース実行
リクエストは最初にコントローラで受け取られ、CreateTableUsecase に処理が委譲されます。このユースケースでは、集約を再構築した上で「テーブル作成イベント」の発行がトリガーされます。
class CreateTableUsecase include Usecase attr_reader :name def execute # ユニークなテーブルIDを生成 table_id = SecureRandom.uuid stream_name = "Table#{table_id}" # 集約のリポジトリを初期化 repository = AggregateRoot::Repository.new # 集約の再構築とイベント発行をトリガー repository.with_aggregate(Table.new(table_id: table_id, name: name), stream_name) do |table| table.create end table_id end end
イベント発行
Table#create メソッドは TableCreated イベントを発行します。イベント発行と同時に、その時点の状態を data フィールドに保存します。
class Table include AggregateRoot def create # apply は Rails Event Store が用意しているイベント発行のメソッド apply TableCreated.new(data: { table_id: table_id, name: name, columns: columns.transform_values(&:to_h) }) end end
イベントが発行されると、以下のようなデータを持つイベントレコードが登録されます。これにより、ある時点の状態を完全に追跡することができます。
{ "name": "my_new_table_123", "columns": { "id": { "name": "id", "type": "integer", "default": null, "nullable": false, "primary_key": true }, "name": { "name": "name", "type": "text", "default": null, "nullable": true, "primary_key": false }, "created_at": { "name": "created_at", "type": "timestamp", "default": null, "nullable": true, "primary_key": false }, "updated_at": { "name": "updated_at", "type": "timestamp", "default": null, "nullable": true, "primary_key": false } }, "table_id": "5de97619-7664-447c-b285-b35b910c935b" }
イベントハンドリングと非同期ジョブ
イベントストアの初期化時に、SyncHandler が特定のイベントをサブスクライブしておくことで、起動する処理を予め設定しておくことができます。
store.subscribe(SyncHandler.new, to: [ TableCreated, TableChanged, TableDeleted ])
Rails Event Store 初期化 - GitHub
SyncHandler は Solid Queue の非同期ジョブをトリガーします。これでイベントに非同期ジョブを連携させることができます。
class SyncHandler def call(event) TableSyncJob.perform_later(event.event_id) end end
テーブル同期ジョブの実行
TableSyncJob は BYODB に向けて実際のテーブル作成処理を行います。その処理結果は、次のフィードバックジョブに伝達されます。
class TableSyncJob < ApplicationJob def perform(event_id) begin event = Rails.configuration.event_store.read.event(event_id) case event.event_type when "TableCreated" # Sequel で BYODB と接続 Sequel.connect(Byodb.url) do |db| db.create_table(table_name) do # カラム定義に基づいてテーブルを動的に作成 table.columns.values.each do |column| name = column.name.to_sym type = column.type.to_sym column.primary_key ? send(:primary_key, name) : send(:column, name, type) end end end # 成功時のフィードバックジョブをトリガー TableFeedbackJob.perform_later(event_id, "success") rescue => e # エラー時のログ出力と失敗時のフィードバックジョブをトリガー Rails.logger.error e.message TableFeedbackJob.perform_later(event_id, "fail") end end end
フィードバックジョブの実行
TableFeedbackJob が処理結果に応じて適切なイベントを発行します。
class TableFeedbackJob < ApplicationJob def perform(event_id, status) event = Rails.configuration.event_store.read.event(event_id) stream_name = "Table#{event.data.fetch(:table_id)}" repository = AggregateRoot::Repository.new case event.event_type when "TableCreated" case status when "success" # テーブル作成成功を確定 repository.with_aggregate(Table.new, stream_name) do |table| table.confirm_created end when "fail" # テーブル作成を取り消し repository.with_aggregate(Table.new, stream_name) do |table| table.reject_created end end end end end
状態の再構築
各イベントに基づいて状態をどのように再構築するかは Rails Event Store の on メソッドで定義します。テーブル作成完了時は、TableCreationConfirmed イベントにより同期フラグを更新しています。
class Table include AggregateRoot # テーブル作成時の状態を定義 on TableCreated do |event| @table_id = event.data.fetch(:table_id) @name = event.data.fetch(:name) @columns = event.data.fetch(:columns).transform_values do |column| Column.new(**column) end @synced = false end # テーブル作成完了時の状態を定義 on TableCreationConfirmed do |event| @table_id = event.data.fetch(:table_id) @synced = true @exists = true end # テーブル作成却下時の状態を定義 on TableCreationRejected do |event| @table_id = event.data.fetch(:table_id) @synced = true @exists = false @error = "Table creation rejected" end end
ここでは単純化された例を紹介しましたが、カラム追加や削除、データ型変更などのより複雑なスキーマ変更においても、過去のスキーマ状態に柔軟にロールバックする処理を定義することが可能です。
まとめ
Rails を用いたイベントソーシングと補償トランザクションの実践を通じて、複数データベース環境における整合性保証の課題に対応するアプローチをご紹介しました。
前提となるローコードプラットフォームの要件は特殊であり、DDL を動的に実行するという難題に対する技術的な挑戦が特徴的な内容だったかと思います。今回提示した手法が必ずしも最適解とは限りませんが、それぞれの判断ポイントにおいて妥当な選定を行った結果として、この構成にたどり着きました。
私自身、イベントストアやドメイン駆動設計を実践するのは、本記事のサンプル実装が初めてであり、試行錯誤を重ねながら取り組みました。もしもより良い構成や改善案があれば、ぜひご意見をお寄せいただけると幸いです。
それでは!
- https://stateofdb.com/databases Airtable などの RDBMS 以外のデータベースも近年主流になりつつあることが背景です↩
- https://dev.mysql.com/doc/refman/9.1/en/cannot-roll-back.html MySQL は DDL をロールバックできません。また Airtable は API ベースでスキーマ変更するためトランザクション機構を有していません↩
- 実践ドメイン駆動設計で紹介されているドメインイベントの概念を部分的に取り入れています↩
- Rails を選んだ理由は、全社的にRailsエンジニアが多く迅速な開発が可能だったためです↩